

还记得之前文章里说的要把所有文章整理成pdf的计划吗?今天我们准备迈出第一步了。
既然确定了用爬虫来自动整理文章,你得先理解爬虫是什么。爬虫说白了就是一个脚本程序。说到脚本,我们平时遇到一些费时费力又容易出错的活儿,都可以把用到的命令写到脚本里,让计算机自动来执行。测试同学说的自动化脚本,运维同学说的环境配置脚本,都是这个意思。一个脚本包含了很多命令,一个接一个,告诉计算机第一步干什么,之后干什么,最后干什么。
在这里,我们的目标很明确,就是写一个爬虫脚本,让计算机一步一步的把「给产品经理讲技术」的所有历史文章,保存成pdf。
历史文章哪里去找?正好,微信公众号的关注界面有一个查看历史消息的链接。
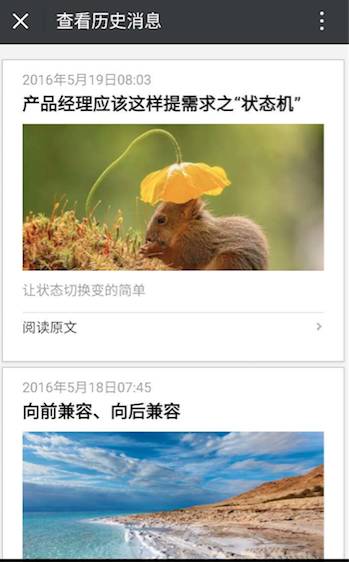
点开历史消息,这个页面每次显示10篇文章,如果用户滑到底,就会再加载10篇出来,典型的异步加载。我们要找的,就是每篇文章的URL地址。只要找到所有文章的URL,就能下载到每篇文章的内容和图片,然后就可以进一步加工处理成pdf了。
为此,我们长按页面选择在浏览器中打开,然后把地址栏里的URL复制出来,发送到电脑上,用Chrome打开。用Chrome的最大好处,就是它有一个「开发人员工具」,可以直接查看网页的源码。按下command+option+L,打开开发人员工具,就能看到这个网页的源码了。我们要找的东西,就藏在这些乱七八糟的HTML代码里。
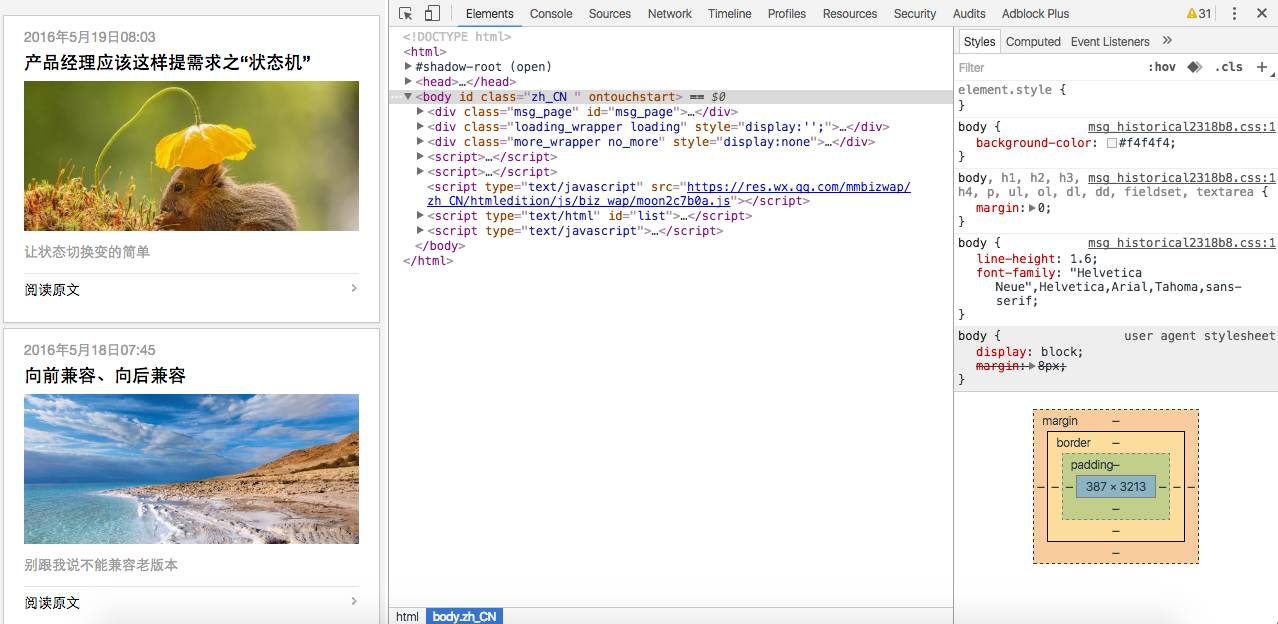
如何从HTML源码里找到我们想要的文章链接?
这要从HTML的结构说起。HTML全称超文本标记语言,所谓标记,就是说是它通过很多标签来描述一个网页。你看到很多像以<XXX>开始,以</XXX>结束的标志,就是标签。这些标签一般成对出现,标签里面还可以套标签,表示一种层级关系。最外面的html标签是最大的,head、body次之,一层一层下来,最后才是一段文字,一个链接。你可以把它类比成一个人,这个人叫html,有head,有body,body上有hand,hand上面有finger。

扯远了,一些常用的标签:
1、<head>。一个网页的很多重要信息,都是在这里声明的。比如说标题,就是在<head>下的<title>里定义的。一个网页用到的CSS样式,可以在<head>下的<style>里定义。还有你写的JavaScript代码,也可以在<head>下的<script>里定义。
2、<body>。它包含的东西就多了,基本上我们能看到的东西,一段文字,一张图片,一个链接,都在这里面。比如说:
<p>表示一个段落
<h1>是一段文字的大标题
<a>表示一个链接
<img>表示一张图
<form>是一个表单
<div>是一个区块
计算机是如何理解HTML的标签的呢?其实很简单,它就是一棵树。你可以把<html>当做树根,从树根上分出<head>和<body>,各个分支上又有新的分支,直到不能再分为止。这有点类似我们电脑上存放的文件。假设你有一本《21天学习C++》的电子书,存在D盘、study文件夹下的CS文件夹里。而study文件夹里除了CS文件夹,还有GRE、岛国文化等目录,代表着另一个分支体系。这也是一棵树。树上的每一片叶子,都有一条从根部可以到达的路径,可以方便计算机去查找。
回到正题,有了这些基础知识,我么再来看微信这个历史消息页面。从最外层的<html>标签开始,一层一层展开,中间有<body>、有<div>、最后找到一个<a>标签,标签里面的hrefs就是每篇文章的URL了。把这个URL复制下来,在新的TAB打开,确认确实是文章的地址。
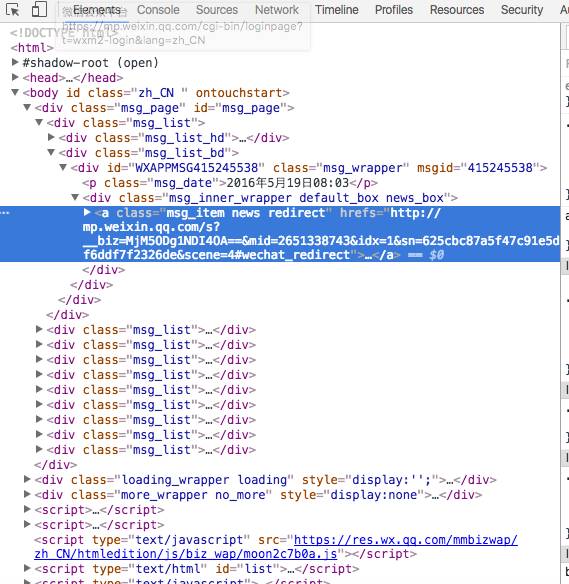
现在我们通过分析一个网页的结构、标签,找到了我们想要的文章URL,我们就可以写爬虫去模拟这个过程了。爬虫拿到网页之后,我们可以用正则表达式去查找这个<a>标签,当然,也可以用一些更高级的手段来找。
但是,这个页面里面毕竟只有10篇文章,我们还要研究它的延迟加载机制,想办法让爬虫能自动找到剩下的文章,这里面会涉及到网络抓包相关的知识,我们后面再聊。
本文来自给产品经理讲技术(微信公众号:pm_teacher)授权发表,转载请联系原作者,违者必究。



- 还没有人评论,欢迎说说您的想法!
