

说起矿工,也许你第一反应是那些挖比特币的机器,不过随着比特币的挖取难度增大,这些矿工的产出也越来越低了。相比之下,网络爬虫算得上是一个输出相当稳定的黄金矿工了,Google、百度这些土豪公司的财富可都是由网络爬虫给挖取出来的,而且还在不断的增加呢...
为什么这么说呢?网络爬虫的作用就是抓取某个指定网页的数据并存储在本地,而Google、百度两家公司的主要收入来源都是搜索引擎,搜索引擎的数据,都是网络爬虫没日没夜地从互联网上抓取回来的,所以说网络爬虫就是他们的黄金矿工。
那么,这些爬虫是怎样寻宝的呢?原理其实很简单,首先给爬虫几个初始的Url链接,然后爬虫把这些链接的网页给抓取回来,经过对网页进行分析之后,可以得到两部分数据:一部分是网页的有效内容,可以用来建立搜索关键词的索引,这部分数据先存储起来;另一部分就是网页中的Url链接了,这些链接又可以作为下一轮爬虫抓取的目标网页了,如此反复操作,也许整个互联网的网页都可以被抓取下来。
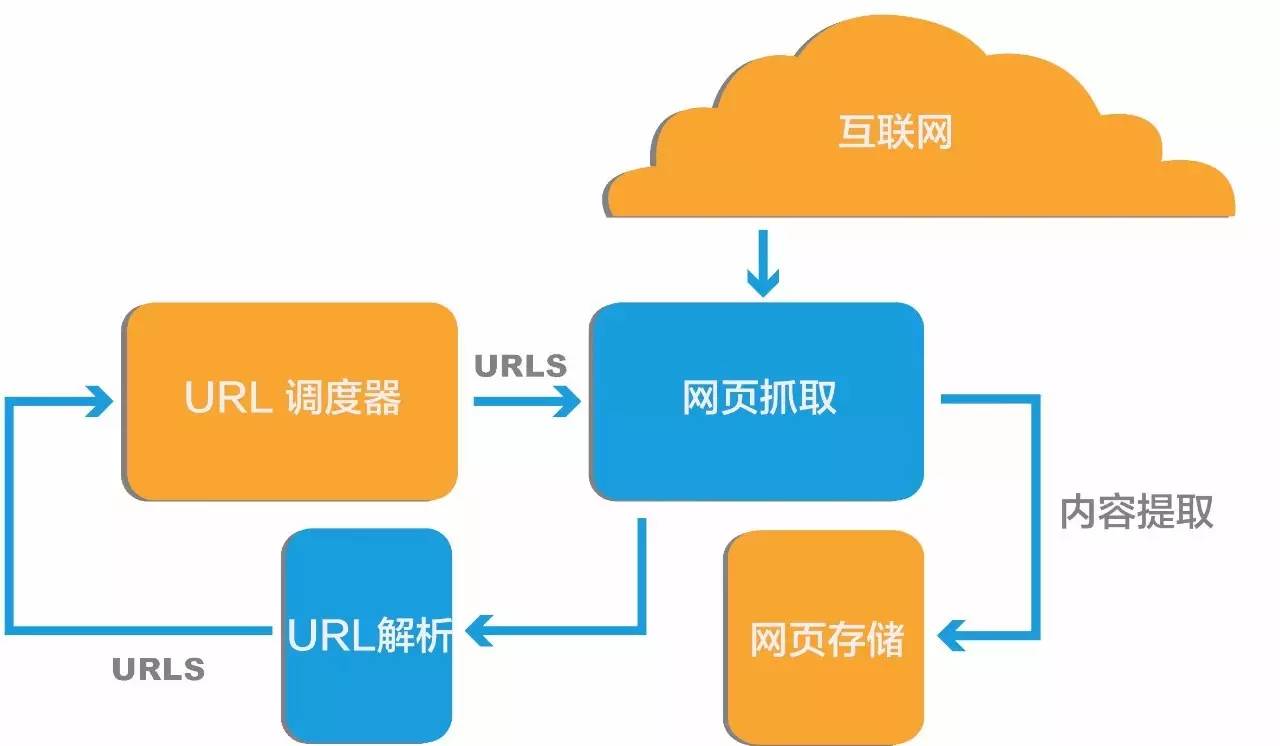
原理虽然很简单,但是要成为一个优秀的矿工,也面临诸多挑战。
一个优秀的黄金矿工,需要有从乱石堆中挑选出黄金的本领,一个优秀的爬虫,可以从页面中解析出正确的Url;
一个优秀的黄金矿工,需要有很快的挖矿速度,一个优秀的爬虫,也必须要有很快的抓取速度;
一个优秀的黄金矿工,总能选择离自己最近的矿石,一个优秀的爬虫,也需要有挑选最有价值的页面进行抓取的能力;
一个优秀的黄金矿工,能适应各种不同的矿场,一个优秀的爬虫,也需要智能的适应不同的网站;
如果你想养出一只黄金爬虫,可以尝试挑战上面四种能力哈~
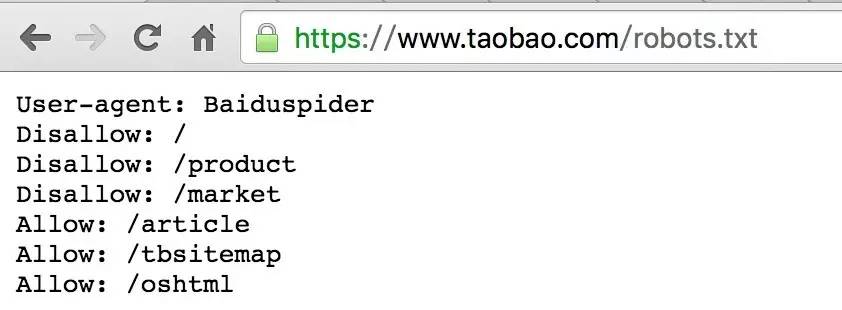
最后再分享一个关于爬虫的冷知识。毕竟爬虫是去抓取别人家的内容给自己带来利益,如果别人不愿意网站内容被你的爬虫抓取,该怎么声明呢?他可以在网站根目录下放一个robots.txt文件,里面可以描述该网站哪些页面可以被抓取,哪些不能够。可以看下淘宝主站的robots文件,里面就不允许百度抓取他家的某些网页...
祝你挖到宝藏~
本文来自给产品经理讲技术(微信公众号:pm_teacher)授权发表,转载请联系原作者,违者必究。



- 还没有人评论,欢迎说说您的想法!
